Nutch的创始人是Doug Cutting,他同时也是Lucene、Hadoop和Avro开源项目的创始人。 Nutch诞生于2002年8月,是Apache旗下的一个用Java实现的开源搜索引擎项目,自Nutch1.2版本之后,Nutch已经从搜索引
”Apache Nutch Java网络爬虫 v1.15“ 的搜索结果
Nutch诞生于2002年8月,是Apache旗下的一个用Java实现的开源搜索引擎项目,自Nutch1.2版本之后,Nutch已经从搜索引擎演化为网络爬虫,接着Nutch进一步演化为两大分支版本:1.X和2.X,这两大分支最大的区别在于2.X对...
增量式更新指的是再更新的时候只更新改变的地方,而为改变的地方则不更新,所以该爬虫。取出待抓取URL,解析DNS得到主机的IP,并将URL对应的网页下载下来,存储进已下载网页库中,并且将这些URL放进已抓取URL队列。...
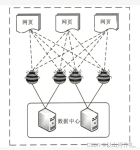


多可网络爬虫是一款独特智能的网络爬虫软件。基于独有的内容评估系统,以及指定与非指定相结合的入口网址技术,实现全智能抓取,无需特别的抓取规则,就能够实现从互联网上持
对现在所有的主流平台爬取是没任何问题!

Internet 的飞速发展加快了网络信息...然而,针对某一特定主题,通用搜索引擎存在信息冗余大、内存占用高、消耗系统资源、查准率低和个性化需求弱等问题 ,为解决这些问题,出现了抓取特定领 域信息资源的主题网络爬虫


代理IP指的是位于互联网上的一台中间服务器,它充当了爬虫与目标服务器之间的中介角色。通过使用代理IP,爬虫可以隐藏真实的IP地址,使得对目标服务器的请求看起来是来自代理服务器而非爬虫本身。通过使用代理IP,...
网络爬虫在各种不同的领域都有广泛的应用。它们可以用来收集,分析,处理和理解大量的在线信息。

一、爬虫是什么? 二、爬虫可以做什么? 三、爬虫开发中有哪些技术?
网络爬虫是一种强大的工具,用于从互联网上的网页中收集和提取数据。Python是一个流行的编程语言,具有丰富的库和框架,使得构建和运行网络爬虫变得相对容易。本文将深入探讨如何使用Python构建一个简单的网络爬虫,...
C语言编写网络爬虫#include #include #include#include #pragma comment(lib, "ws2_32.lib")//加载网络支持的库#define _M_MPPCusing namespace std;/************************************************************...
什么是网络爬虫 网络爬虫又称网络蜘蛛,是指按照某种规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常包含其他网页的入口,网络爬虫则通过一个网址依次进入其他网址获取所需内容。 优先申明:...
网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫。 实际的网络爬虫系统通常是几种爬虫技术相结合实现的 通用网络爬虫 通用网络爬虫又称...
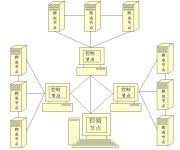
聊一聊Python与网络爬虫。1、爬虫的定义爬虫:自动抓取互联网数据的程序。2、爬虫的主要框架爬虫程序的主要框架如上图所示,爬虫调度端通过URL管理器获取待爬取的URL链接,若URL管理器中存在待爬取的URL链接,爬虫...
『哈士奇赠书33期』- 『Python网络爬虫入门到实战』
python简单实现网络爬虫
标签: python




推荐文章
- 联邦学习综述-程序员宅基地
- virtuoso--工艺库答疑_tsmc mac-程序员宅基地
- C++中的exit函数_c++ exit-程序员宅基地
- Java入门基础知识点总结(详细篇)_java基础知识重点总结-程序员宅基地
- 【SpringBoot】82、SpringBoot集成Quartz实现动态管理定时任务_springboot集成quratz 实现动态任务调度-程序员宅基地
- testNG常见测试方法_idea_java_testng 测试-程序员宅基地
- Debian11系统安装-程序员宅基地
- Centos7重置root用户密码_centos7更改root密码-程序员宅基地
- STM32常用协议之IIC协议详解_正点原子stm32 iic-程序员宅基地
- 【视频播放】Jplayer视频播放器的使用_jplayer 播放amr-程序员宅基地